За останні кілька років машинне навчання (ML) непомітно стало невід’ємною частиною нашого повсякденного життя. Це впливає на все: від персоналізованих рекомендацій на сайтах для покупок і потокових передач до захисту наших вхідних повідомлень від спаму, який ми отримуємо щодня. Але це не просто інструмент для нашої зручності. Машинне навчання стало вирішальним у поточному технологічному ландшафті, і, схоже, це не зміниться найближчим часом. Воно використовується, щоб розблокувати приховану інформацію в даних, автоматизувати завдання та процеси, покращити процес прийняття рішень і розширити межі інновацій.
В основі цієї технології – алгоритми машинного навчання . По суті, це комп’ютерні програми, розроблені для вивчення даних без явного програмування для окремих завдань. Вони використовуються для постійного аналізу інформації, адаптації своєї структури та вдосконалення з часом.
Давайте розглянемо 11 популярних алгоритмів машинного навчання та дізнаємось, що вони роблять і для чого їх можна використовувати. Щоб це було легше, список поділено на чотири категорії:
- Контрольоване навчання
- Навчання без контролю
- Ансамбль
- Навчання з підкріпленням
Контрольоване навчання
1. Лінійна регресія
Завдяки своїй простоті лінійна регресія виділяється як зручний для початківців алгоритм машинного навчання. Він встановлює лінійні зв’язки між однією змінною та однією чи кількома іншими змінними. Наприклад, інструмент для нерухомості може знадобитися аби відстежувати зв’язок між ціною будинку (залежна змінна) і квадратними метрами (незалежна змінна). Він вважається «контрольованим», тому що вам потрібно надати йому позначені дані, щоб навчити його створювати ці з’єднання.
Його відносна простота робить його дуже ефективним при роботі з великими наборами даних, а вихідні дані легко інтерпретувати та ідентифікувати глибокі тенденції. Однак ця ж простота також є причиною, чому він бореться зі складнощами. Нелінійні візерунки можуть заплутати його, і він може бути легко вибитий з колії викидами. Вам також потрібно бути обережним у виборі правильних змінних. В іншому випадку якість виходу може серйозно погіршитися.
2. Логістична регресія
Замість того, щоб зосереджуватися на з’єднаннях, алгоритми логістичної регресії використовуються для прийняття двійкових рішень, наприклад «спам» або «не спам» для електронних листів. Він передбачає ймовірність приналежності екземпляра до певного класу за допомогою різних факторів, які він надає. Це також може надати уявлення про те, які фактори найбільше впливають на результат.
Як і лінійна регресія, він добре обробляє великі набори даних, але також має деякі з тих самих недоліків. Він також передбачає лінійні зв’язки, тому складні, нелінійні візерунки створюватимуть проблеми. Якщо дані, які він аналізує, не збалансовані, це також може створити дисбаланс у його прогнозах. Наприклад, якщо більшість електронних листів, які він переглядає, не є спамом, йому може бути важко ідентифікувати такі листи.
3. Підтримка векторних машин (SVM)
Замість того, щоб робити прогнози, алгоритми SVM знаходять найширшу межу між класами даних. Таким чином, замість того, щоб передбачати, які листи є «спамом» чи «не спамом», він по суті проводить лінію, щоб чітко розділити електронні листи на ці дві категорії.
Оскільки вони зосереджені на найважливіших даних і не піддаються обману нерелевантними деталями, алгоритми SVM чудово підходять у просторі великої розмірності. Він також не буде виведен з колії через викиди завдяки тому, що зосереджен на підмножині точок даних. Але він також дорогий з точки зору обчислень, і навчання може бути повільним. Його заключення також може бути важко інтерпретувати через складність, а вибір правильних параметрів для функції ядра потребує часу та ретельного налаштування.
4. Дерева рішень
Як випливає з назви, дерева рішень мають структуру, подібну до дерева, яка задає серію запитань для отримання відповіді «так» або «ні». Думайте про це як про блок-схему, де ви продовжуєте приймати рішення, доки не дійдете остаточної відповіді. Ця остаточна відповідь є вашим прогнозом. Дерева рішень — це універсальні контрольовані алгоритми машинного навчання, які використовуються для вирішення проблем класифікації та регресії.
Найкраще в алгоритмі дерева рішень те, що його легко зрозуміти. Ви можете легко слідувати логіці, дивлячись на кожне рішення, яке він приймає. Він також дуже гнучкий, здатний обробляти різні типи даних і може продовжувати приймати рішення, незважаючи на відсутність даних. На жаль, він також схильний до помилок та дуже чутливий до порядку та вибору функцій. Він також може помилитись зі складними зв’язками між змінними, що робить його менш точним для складних проблем.
5. kNN і ANN
Так звані алгоритм найближчого сусіда (ANN) і алгоритм k-найближчого сусіда (kNN) пов’язані з пошуком подібності та використовуються в машинному навчанні для різних цілей. Алгорітми створюють категорію точок даних, знаходячи найбільш схожі точки з даних навчання та роблять з них окрему категорію.
Простіше кажучи, обидва ці алгоритми призначені для визначення схожих точок даних, наприклад схожих продуктів на сайті електронної комерції. Це універсальні алгоритми, які можуть обробляти різні типи даних без зайвої попередньої обробки і вони чудово підходять для пошуку найближчого сусіда та виявлення аномалій. Але вони обидва також можуть помилятись, оскільки дані розподіляються по багатьох вимірах, і може бути важко зрозуміти, як вони прийшли до свого рішення.
6. Нейронні мережі
Алгоритми нейронної мережі — основа більшості сучасних інструментів ШІ — мають на меті імітувати структуру людського мозку. Вони роблять це, використовуючи шари взаємопов’язаних штучних «нейронів», які за допомогою обробки даних навчаються знаходити шаблони в даних. Нейронні мережі використовуються для різних завдань, таких як розпізнавання образів, класифікація, регресія та кластеризація.
Нейронні мережі на сьогоднішній день є найпотужнішим і домінуючим алгоритмом машинного навчання, здатним виконувати різноманітні завдання від розпізнавання зображень до обробки природної мови . Вони також надзвичайно гнучкі та можуть автоматично вивчати відповідні функції з вихідних даних. Вони можуть робити це постійно, а отже, адаптуються до змін. Вони також дуже потребують даних, вимагаючи величезних обсягів даних для навчання, що може стати проблемою, якщо таких даних немає. Через природу нейронних мереж як чорного ящика зрозуміти, як вони досягають своїх прогнозів, може бути дуже важко.
Навчання без контролю
7. Кластеризація
Алгоритм кластеризації — це тип алгоритму неконтрольованого машинного навчання, який групує разом схожі точки даних. Мета полягає в тому, щоб виявити природні структури в даних, не вимагаючи мічених результатів. Подумайте про це як про сортування камінчиків, групуючи їх за схожістю кольору, текстури чи форми. Ці алгоритми можна використовувати для різних програм, включаючи сегментацію клієнтів, виявлення аномалій і розпізнавання шаблонів.
Оскільки кластеризація не контролюється, алгоритми не вимагають мічених даних. Вони чудово виявляють шаблони та допомагають у стисненні даних шляхом групування схожих даних. Однак ефективність цілком залежить від того, як ви визначаєте схожість. І зрозуміти логіку кластерних алгоритмів може бути складно.
8. Виявлення аномалій і викидів
Виявлення аномалій (також відоме як виявлення викидів) — це процес ідентифікації випадків у наборі даних, коли дані суттєво відрізняються від очікуваної або «нормальної» поведінки. Ці аномалії можуть приймати форму викидів, новинок або інших нерівностей. Алгоритми аномалій чудово підходять для таких завдань, як кібербезпека, фінанси та виявлення шахрайства.
Їм не потрібно навчатися на позначених даних, тому їх можна використовувати навіть на необроблених даних, де аномалії є рідкісними або невідомими. Однак вони також дуже чутливі до порогових значень, тому збалансувати помилкові позитивні та негативні результати може бути складно. Їх ефективність також часто залежить від вашого розуміння основних даних і очікуваних проблем. Вони можуть бути надзвичайно потужними, але чим складніший алгоритм, тим важче зрозуміти, чому щось могло бути позначено як аномалія.
Моделі ансамблю
9. Випадкові ліси
Випадкові ліси (або ліси випадкових рішень) — це методи ансамблевого навчання, які використовуються для класифікації, регресії та інших завдань. Вони працюють, будуючи колекцію дерев рішень під час навчання.
Використовуючи групу дерев рішень, випадкові ліси можуть давати набагато точніші та надійніші результати, а також вони можуть обробляти різні типи даних. Їх відносно легко інтерпретувати, оскільки ви можете аналізувати рішення на рівні окремого дерева, але для більш складних рішень може бути важко зрозуміти, як вони туди потрапили. Через велику кількість обчислювальної потужності, яку вони потребують, використання випадкових лісів також може бути дорогим.
10. Посилення градієнта
Підсилення градієнта — це ще один потужний комплексний метод, який послідовно об’єднує кілька слабких елементів навчання, як-от дерева рішень, для ітеративного підвищення точності прогнозування. Це як мати команду учнів, кожен з яких спирається на помилки попереднього, що зрештою призводить до міцнішого колективного розуміння.
Поєднуючи кілька дерев (або інше навчання), посилення градієнта може обробляти складні зв’язки з високою точністю та гнучкістю. Вони також дуже стійкі до викидів, оскільки менш сприйнятливі до впливу окремих точок даних порівняно з іншими алгоритмами. Однак, подібно до випадкових лісів, їх використання може бути дуже дорогим. Знаходження оптимальних параметрів, необхідних алгоритму для отримання найкращих результатів, також може зайняти час.
Навчання з підкріпленням
11. Q-навчання
Q-навчання — це безмодельний алгоритм навчання з підкріпленням, який використовується для вивчення значення дії в певному стані. Думайте про це як про агента, який орієнтується в лабіринті — навчаючись методом проб і помилок, щоб знайти найшвидший шлях до середини. Це суть Q-навчання, хоча й у дуже спрощеному вигляді.
Найбільша перевага алгоритмів Q-навчання полягає в тому, що вам не потрібна детальна модель середовища, що робить його дуже адаптивним. Він також може працювати з великими просторами станів, тому ідеально підходить для складних середовищ із багатьма можливими станами та діями. Це чудово, але не завжди легко знайти баланс між спробами нових дій (дослідження) і максимізацією відомих винагород (експлуатація). Він також має високі обчислювальні витрати, і його заключення потрібно ретельно масштабувати, щоб забезпечити ефективне навчання.
Алгоритми машинного навчання в корпоративних рішеннях
Машинне навчання швидко стало потужним інструментом, що стимулює інновації та ефективність у багатьох галузях. Корпоративні рішення все частіше використовують ці алгоритми для вирішення складних проблем, оптимізації операцій і отримання цінної інформації з даних. Це й не дивно, враховуючи глибину та різноманітність 11 алгоритмів, які ми розглянули. Але що осталось поза увагою – це пошук і отримання даних як одне із головних завдань бізнесу. Крім того, як вже казали, висновки алгоритмів можуть бути хібними, якщо вхідні данні нестандартизовані. За вирішення цих проблем взялися у компанії Elastic. Там більш ніж усвідомлюють силу та потенціал машинного навчання, тож створили набір рішень, які готові надати підприємствам безпомилкові можливості машинного навчання. Від пошуку та аналізу даних у реальному часі за допомогою Elasticsearch і Kibana до прогнозування потенційних проблем у програмах за допомогою Elastic APM , машинне навчання стало ключовим гвинтиком у розробленій Elastic машини. А в сфері безпеки тут використовують виявлення аномалій для виявлення загроз, одночасно персоналізуючи пошук за допомогою таких алгоритмів, як кластеризація.
Сподіваємось, тепер ви розумієте, наскільки різноманітними та важливими можуть бути алгоритми машинного навчання, і, можливо, навіть у вас виникла ідея про те, як ви можете їх використовувати самостійно. Тож можете безкоштовно завантажити рішення Elastic з сайту розробника та спробувати.
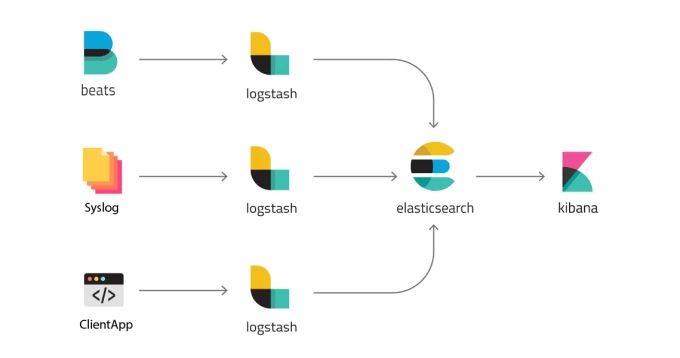
Що ви отримаєте тут? Elastic — це компанія, яка пропонує набір програмних рішень та інструментів для збору, пошуку, аналізу та візуалізації даних. Основні продукти Elastic включають:
- Elasticsearch — розподілений пошуковий та аналітичний движок з відкритим кодом, який забезпечує швидкий пошук по величезних обсягах даних.
- Kibana — інструмент візуалізації для аналізу та створення панелей моніторингу для даних, збережених в Elasticsearch.
- Logstash — інструмент для збору, обробки та передачі даних з різних джерел в Elasticsearch.
- Beats — легковажні агенти передачі даних, які передають дані від різноманітних джерел в Logstash або безпосередньо в Elasticsearch.
Рішення Elastic використовуються для централізованого логування, моніторингу інфраструктури, аналізу безпеки, бізнес-аналітики, пошукових систем та багатьох інших випадків застосування, коли потрібно ефективно зберігати, шукати та аналізувати великі обсяги різнорідних даних. Постачальником рішень Elastic в Україні є компанія Ідеалсофт.