Splunk і Elastic/ELK Stack є двома найпопулярнішими платформами для керування журналами та спостереження. Обидва вони здатні збирати, аналізувати та зберігати великі обсяги даних, і кожен із них надає широкий спектр функцій для пошуку, фільтрації, аналізу та візуалізації зібраних даних.
Незважаючи на те, що інструменти дуже схожі, є деякі ключові відмінності, на які слід звернути увагу. Splunk — це запатентований інструмент, який, як правило, вважається більш зручним для користувача та легшим для початку, ніж стек Elastic. Він орієнтований на корпоративних клієнтів, тому має ширший спектр функцій і функцій, включаючи підтримку машинного навчання та інші розширені аналітичні можливості.
З іншого боку, Elastic Stack — це група продуктів, які об’єднані разом для збору, пошуку та візуалізації машинних даних. Він також зазвичай вважається більш придатним, ніж Splunk, для обробки дуже великих обсягів даних.
Давайте порівняємо ці два провідні інструменти SIEM один з одним і порівняємо їхні функції, сильні та слабкі сторони, щоб вирішити, який із них найкраще відповідає вашим потребам.
Що таке Splunk?
- Інтерфейс користувача Splunk
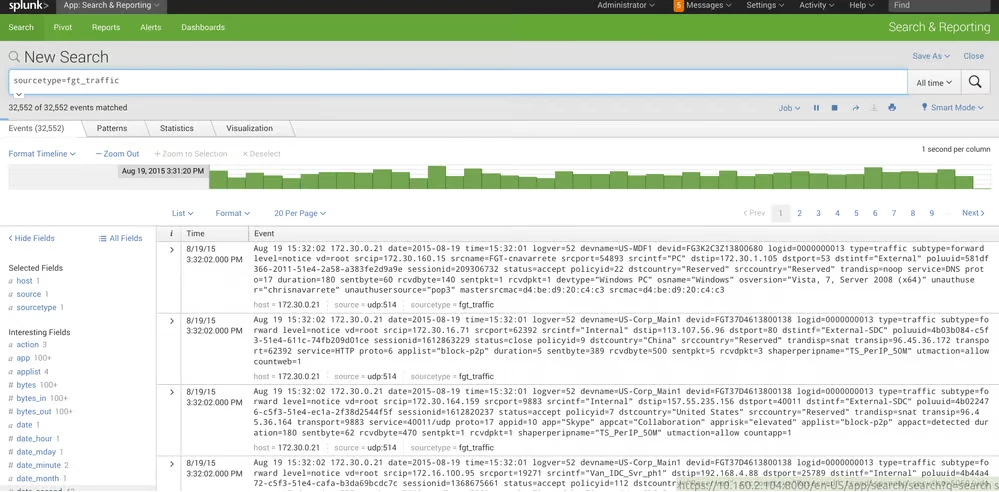
Splunk — це власна платформа безпеки та спостереження. Він призначений для індексування великих обсягів машинних даних (журналів, подій і показників) із різноманітних джерел і надання ряду функцій для пошуку, аналізу та візуалізації цих даних, щоб надати цінну інформацію про спостережуваність.
По суті, вам потрібно передати машинні дані в Splunk, і він виконає брудну роботу з обробки таких даних, щоб витягти лише важливі біти, які допоможуть вам легко діагностувати проблеми та можливості для вдосконалення.
Він часто використовується організаціями для керування журналами, аналізу безпеки, моніторингу відповідності, бізнес-аналітики та багато іншого для всієї інфраструктури. Його власна мова пошуку під назвою Search Processing Language (SPL) використовується для запитів зібраних наборів даних, і це дозволяє легко створювати візуалізації, сповіщення та інформаційні панелі з неструктурованих даних, що зазвичай є виснажливим процесом.
Splunk відомий своїм зручним інтерфейсом і простотою використання. Він також має широкий спектр функцій і можливостей, включаючи підтримку машинного навчання та інші розширені аналітичні можливості. Це робить його популярним вибором для організацій будь-якого розміру та галузей.
Що таке стек Elastic/ELK?
- Інтерфейс користувача Elasticsearch
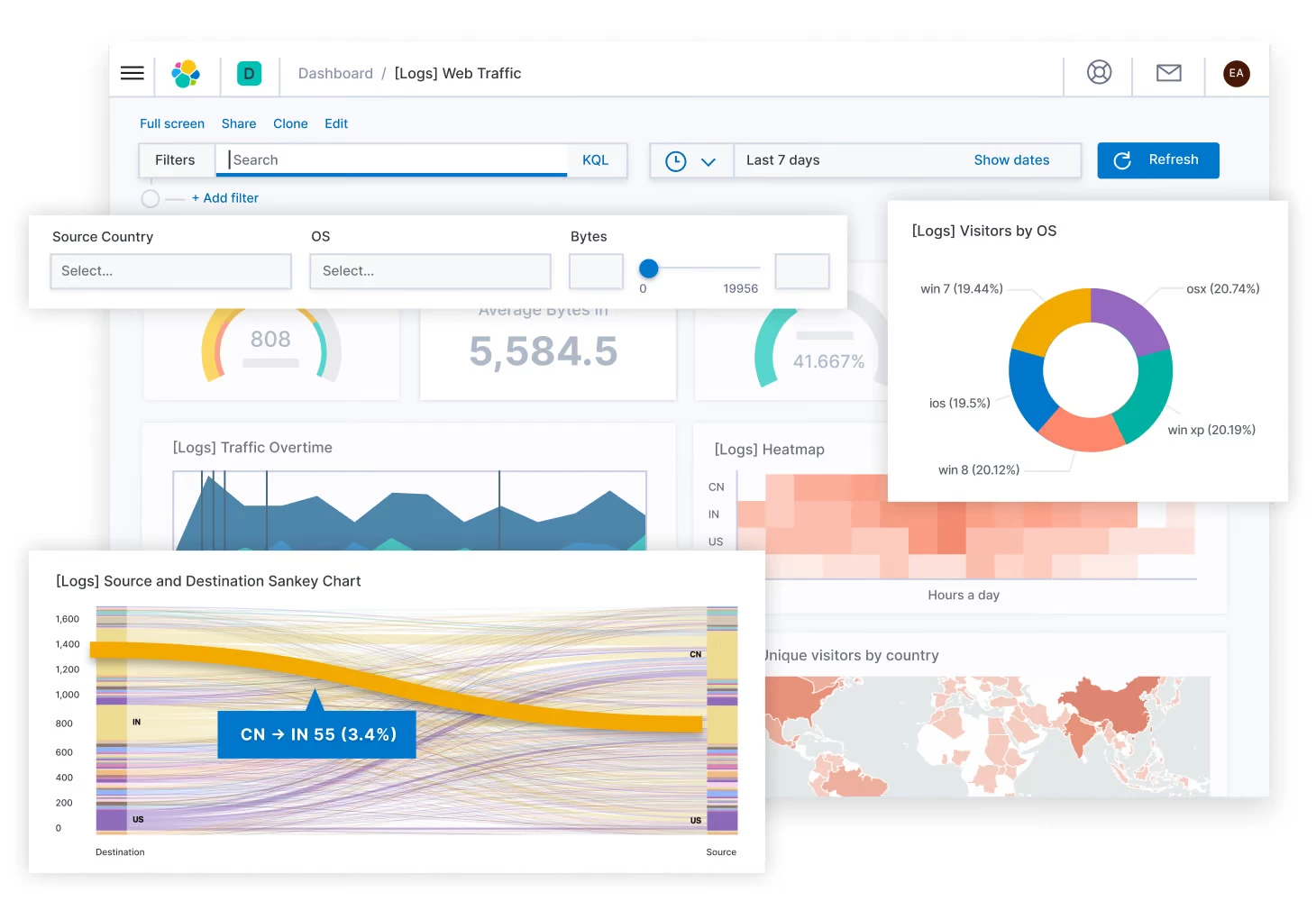
Як згадувалося раніше, Elastic Stack — це набір інструментів для прийому, збагачення, зберігання, аналізу та візуалізації даних. Він розроблений, щоб допомогти користувачам керувати великими обсягами даних і полегшити пошук, аналіз і візуалізацію цих даних у реальному часі.
Elastic Stack раніше був відомий як стек ELK, що є абревіатурою від Elasticsearch , Logstash і Kibana . Elasticsearch — це пошукова система та аналітична платформа, Logstash — конвеєр обробки даних, Kibana — інструмент візуалізації даних. Нещодавно Beats було додано до стеку як спосіб збору даних із різних джерел, що призвело до ребрендингу.
При спільному використанні ці інструменти утворюють потужну платформу для роботи з великими наборами даних у режимі реального часу. Компанії часто використовують аналіз стекових журналів Elastic/ELK, аналітику в реальному часі та інші випадки використання, коли пошук, аналіз і візуалізація великих наборів даних є важливими.
Ключові моменти, на які слід звернути увагу, вибираючи між Splunk і Elastic Stack
- Поглинання даних
Перш ніж обидві платформи зможуть працювати з вашими даними, вам потрібно спершу надіслати їм дані. Машинні дані часто мають різні формати та типи, тому вкрай важливо знати, що підтримує кожна платформа та як отримати дані із середовища вашого додатка у відповідні конвеєри.
Splunk може отримувати машинні дані в різних форматах, включаючи XML, JSON, CSV, TSV та інші структуровані формати. Він також працює з напівструктурованими або навіть неструктурованими даними, які потім можна моделювати у структурований формат відповідно до ваших вимог.
Надсилання даних до Splunk також є досить простим, оскільки він пропонує різноманітні параметри залежно від джерела даних, з яким ви працюєте, зокрема:
- Служба Ingest для збору об’єктів JSON із кінцевих точок /events і /metrics API REST Ingest.
- Служба пересилання даних для збору даних за допомогою пересилачів Splunk.
- Потокові з’єднувачі для безперервного отримання даних, які надсилають такі джерела даних, як Apache Kafka , Amazon Kinesis Data Stream, Google Cloud Pub/Sub та інші.
У стеку Elastic/ELK саме Logstash відповідає за доставку машинних даних від джерела до місця призначення. Зазвичай він використовується для обробки великих обсягів журнальних даних, таких як журнали програм, журнали веб-сервера та журнали операційної системи. Він працює зі структурованими та неструктурованими даними, а також може аналізувати та витягувати відповідні деталі з даних, які потім можна трансформувати та збагачувати за допомогою різноманітних вбудованих фільтрів і плагінів. Потім дані нарешті направляються до Elasticsearch.
Beats також є ще одним способом доставки даних у Elastic Stack. Це одноцільові та легкі служби, які ви встановлюєте на своїх серверах для збору всіх типів машинних даних (таких як журнали, показники або мережеві пакетні дані), як вважаєте за потрібне. Наприклад:
- Filebeat хвости і журнали кораблів.
- Heartbeat надсилає дані моніторингу безвідмовної роботи.
- Packetbeat передає мережеві дані.
- і більше!
- Індексація
Індекси використовуються для організації та пошуку введених даних, і їх можна порівняти з базою даних у схемі реляційної бази даних. Це означає, що документи в індексі зазвичай пов’язані один з одним. Наприклад, ви можете мати індекс для користувачів і інший для продуктів.
Коли дані надходять, вони автоматично індексуються, що означає, що вони обробляються та додаються до одного або кількох індексів. Індексування є важливою частиною конвеєра прийому даних, оскільки воно дозволяє обом платформам швидко й ефективно шукати й отримувати дані.
У Elasticsearch індекси представляють найбільшу сутність, до якої можна надсилати запити. Кожен індекс ідентифікується за допомогою унікального імені під час виконання операцій індексування, пошуку, оновлення та видалення документів у ньому.
Індекси Elasticsearch
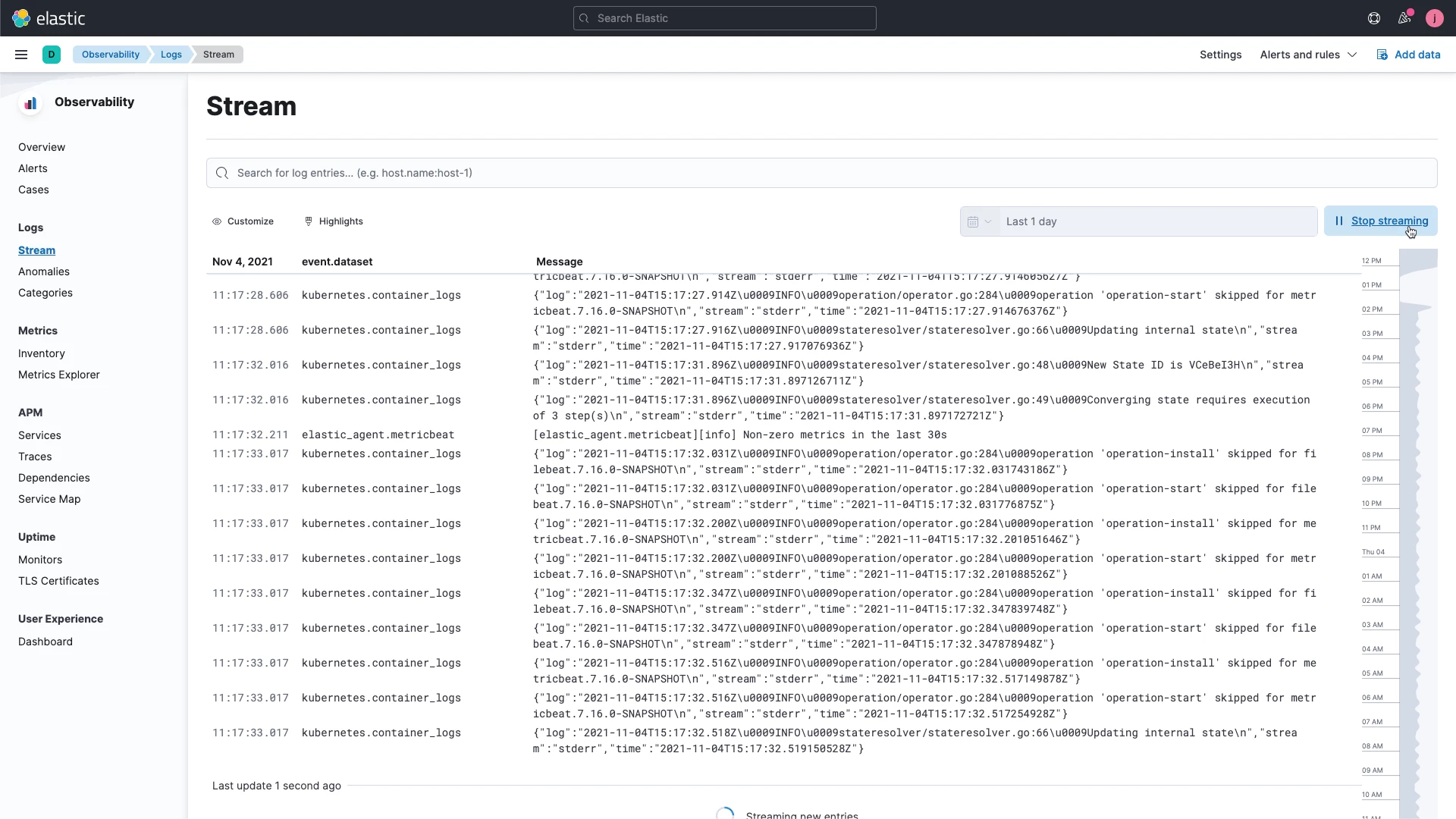
Індекси в Elasticsearch використовують інвертовану структуру даних індексу, яка зберігає зіставлення вмісту (наприклад, рядків або чисел) з одним або кількома документами, що забезпечує найкращі збіги для повнотекстового пошуку навіть із величезних наборів даних. Щоб індексувати дані в Elasticsearch, ви можете використовувати _indexAPI, який дозволяє додавати документ JSON до індексу. Ви також можете мати необмежену кількість індексів.
Індекси Splunk
Splunk використовує свій компонент індексатора для індексування журналів, надісланих засобом пересилання Splunk. Він аналізує кожен запис даних, щоб отримати значення за замовчуванням, такі як хост, джерело події та тип джерела, і налаштовує кодування символів. Потім він розбиває дані на рядки та визначає позначки часу або створює їх для сортування окремих подій за часом. Його також можна використовувати для маскування конфіденційних даних на цьому етапі.
Після етапу синтаксичного аналізу дані поміщаються в сегменти, за якими можна здійснювати пошук. Рівень сегментації впливає на швидкість, можливості пошуку та ефективність стиснення. Потім дані записуються на диск і стискаються. Ключовою перевагою індексатора Splunk є те, що він зберігає кілька копій даних, щоб мінімізувати ризик втрати даних.
- Візуалізація даних
Візуалізація даних у стеку Elastic/ELK обробляється Kibana. Після того, як ваші дані проіндексовані в Elasticsearch, ви можете використовувати Kibana для створення різноманітних візуалізацій, таких як лінійні графіки, стовпчасті діаграми та кругові діаграми, щоб отримати розуміння даних.
Приладові панелі Kibana
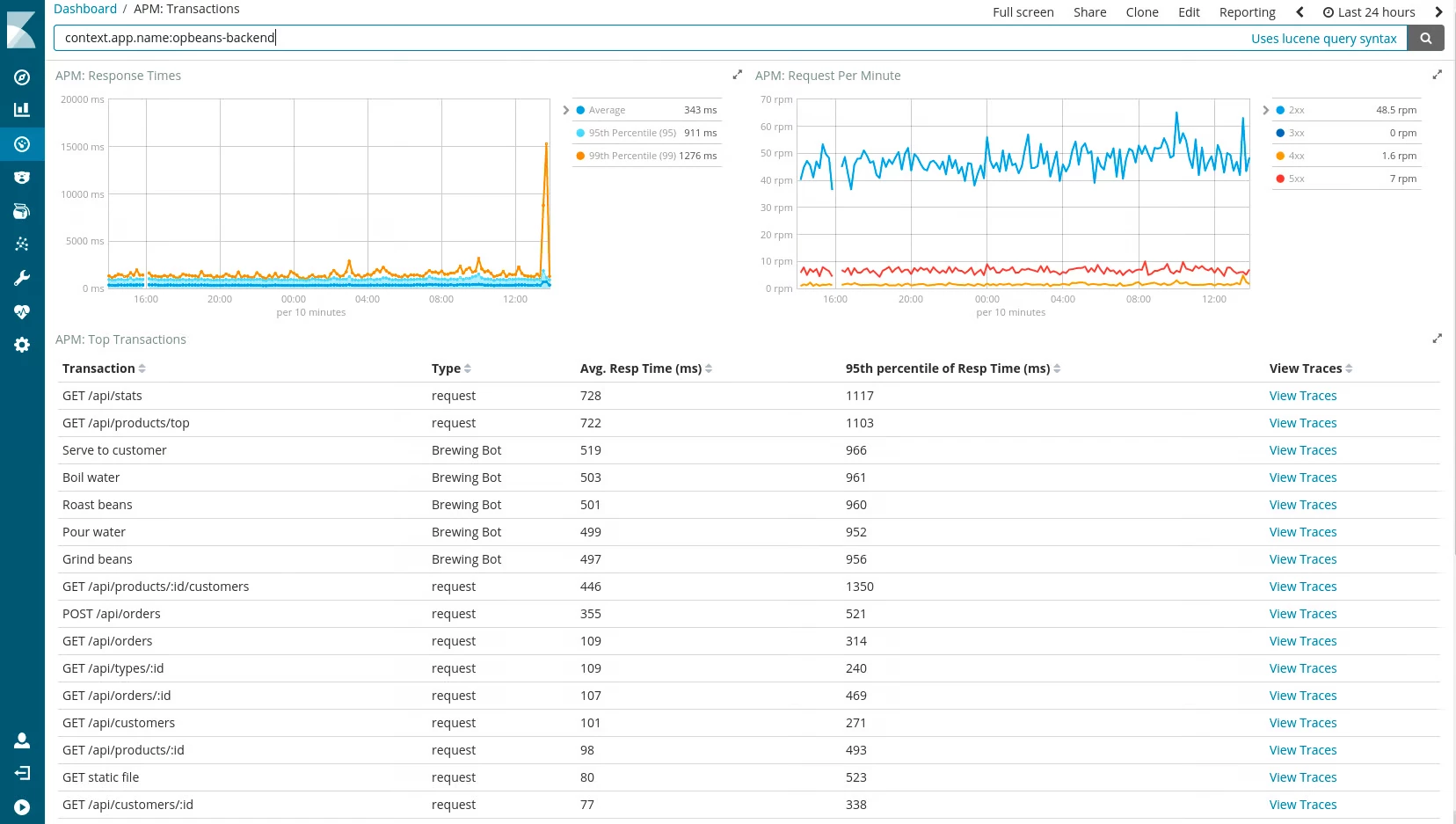
Коли ви входите в Kibana, ви можете запитувати проіндексовані дані та звузити результат до конкретних даних, які ви хочете візуалізувати. Потім ви можете вибрати бажаний тип візуалізації (наприклад, лінійний графік, гістограма, секторна діаграма) і скористатися параметрами в редакторі, щоб налаштувати їх вигляд. Зберігши візуалізацію, ви можете додати її на інформаційну панель або поділитися з іншими, створивши на неї посилання або експортувавши її до зображення чи PDF-файлу.
Приладові панелі Splunk
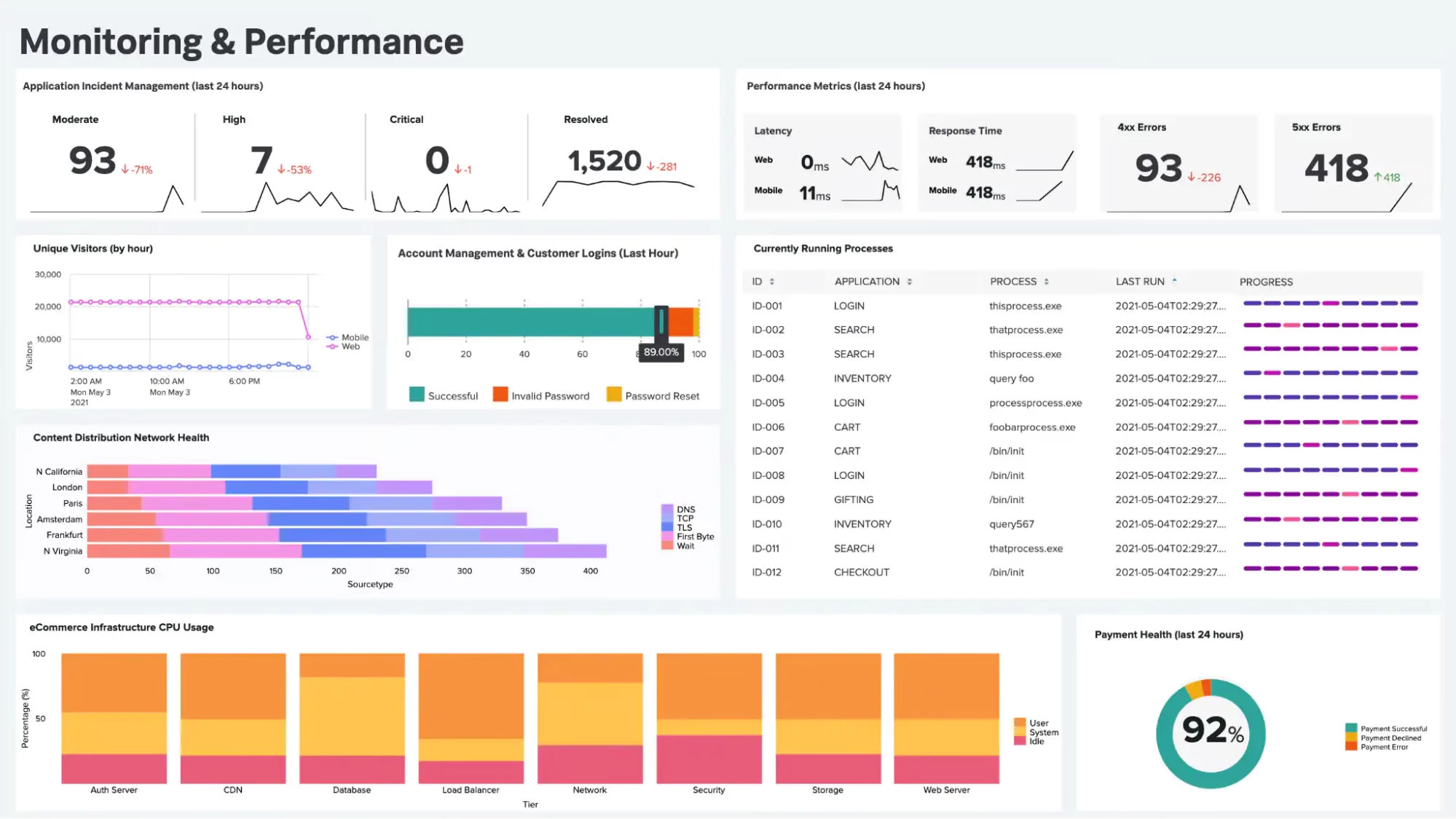
Інтерфейс Splunk Dashboards також дозволяє користувачам візуалізувати зведені дані. Інформаційні панелі складаються з панелей, що містять різні модулі, такі як діаграми, графіки, вхідні дані, поля тощо. Ви можете підключити їх до збереженого пошуку та переглядати результати в реальному часі, коли вони оновлюються у фоновому режимі.
- Налаштування та обслуговування
І Splunk, і Elasticsearch є потужними інструментами для аналізу та візуалізації даних. Однак процес налаштування та налаштування цих інструментів може бути зовсім іншим.
Elasticsearch — це система розподіленого пошуку та аналітики, що означає, що вона розроблена для роботи на кількох серверах у кластері. Щоб налаштувати його, вам потрібно встановити програмне забезпечення на кожному сервері в кластері, а потім налаштувати сервери для обміну даними один з одним. Зазвичай це передбачає встановлення параметрів мережі та безпеки, а також визначення ролей і обов’язків кожного сервера в кластері. Після того, як кластер буде запущено, ви зможете використовувати такі інструменти, як Logstash і Kibana, щоб отримати та візуалізувати дані в Elasticsearch.
Налаштувати Splunk трохи простіше. Вам потрібно встановити програмне забезпечення Splunk на сервері та слідувати вказівкам майстра встановлення. Зазвичай це передбачає вказівку каталогу для даних і журналів Splunk, а також налаштування облікового запису користувача та пароля. Після завершення інсталяції ви можете увійти до веб-інтерфейсу Splunk і почати отримувати та аналізувати дані.
Підводячи підсумок, можна сказати, що налаштування Splunk легше та вимагає менше технічних знань, тоді як Elasticsearch вимагає глибшого розуміння розподілених систем.
- Інтерфейс користувача
І Splunk, і Elasticsearch мають веб-інтерфейси користувача, які дозволяють виконувати різноманітні завдання, такі як прийом, аналіз і візуалізація даних. Однак користувацькі інтерфейси цих двох інструментів досить відрізняються за дизайном і функціональністю.
Splunk log спостерігач
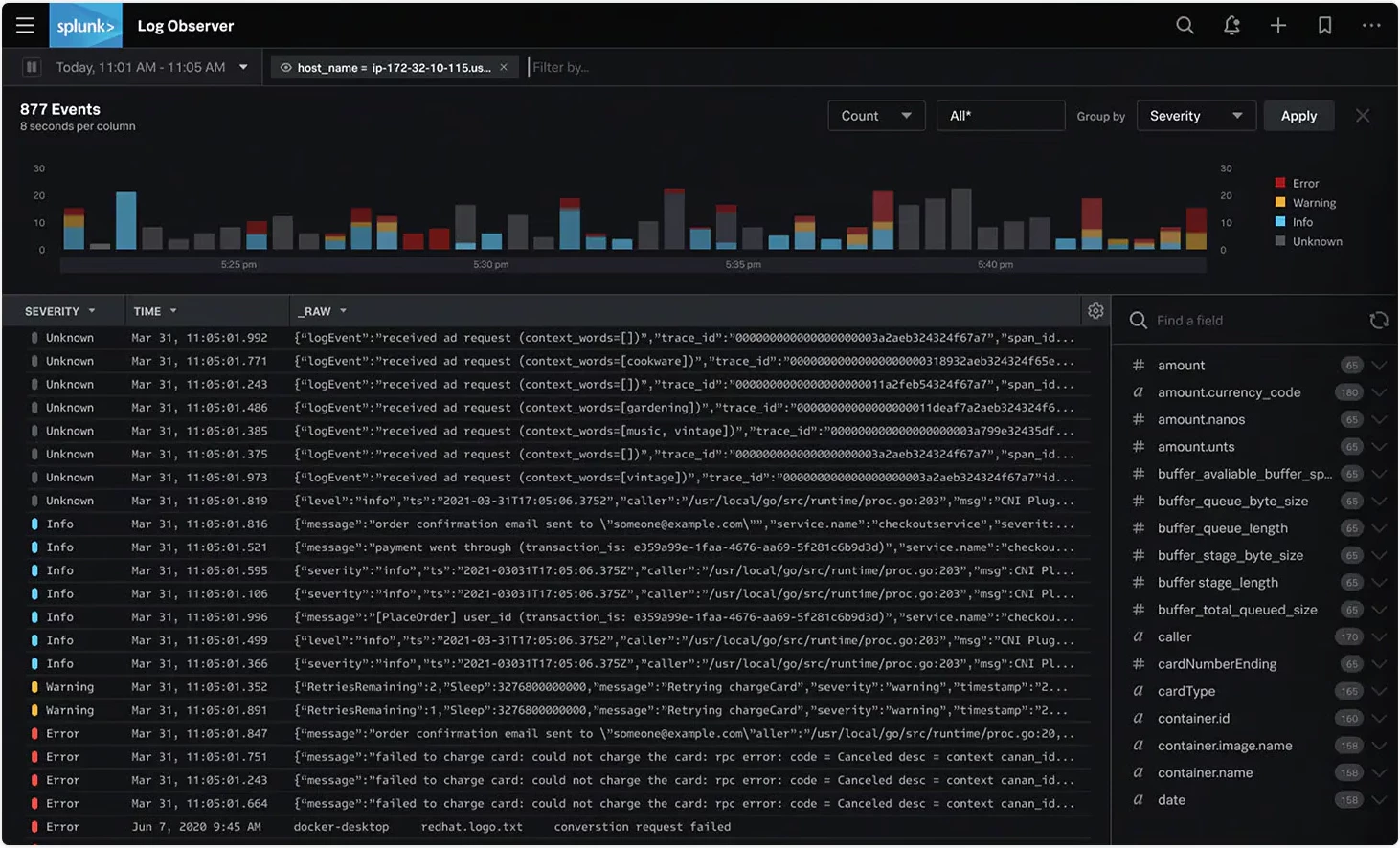
Інтерфейс користувача Splunk орієнтований на аналітику на основі пошуку та містить панель пошуку у верхній частині екрана. Це дозволяє вводити пошукові запити та переглядати результати в реальному часі. Користувальницький інтерфейс також містить низку попередньо створених інформаційних панелей і візуалізацій, які дозволяють швидко й легко отримувати аналіз отриманих даних.
З іншого боку, інтерфейс користувача Kibana зосереджений на виявленні та дослідженні даних. Він містить низку готових засобів візуалізації та аналізу даних, таких як програми Discover, Visualize та Dashboard. Ці інструменти також дозволяють швидко й легко досліджувати та аналізувати ваші дані без необхідності писати складні пошукові запити.
Інтерфейс Kibana
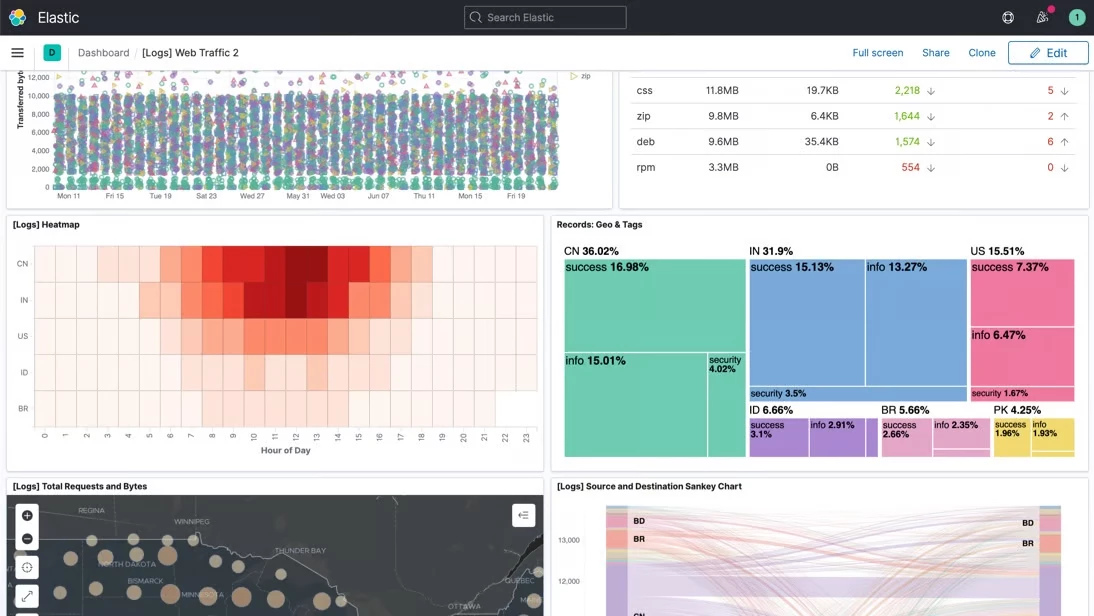
Загалом інтерфейси користувача Splunk і Elastic Stack призначені для різних цілей і забезпечують різну функціональність. Splunk зосереджено на аналітиці на основі пошуку, тоді як Elasticsearch зосереджено на виявленні та дослідженні даних.
Вибір між стеком Splunk і Elastic/ELK
Загалом вибір між Splunk і Elastic/ELK залежить від конкретних потреб вашої організації та наявних у вас ресурсів. Якщо вам потрібне надійне та зручне рішення, яке може виконувати широкий спектр завдань із керування та аналізу журналів, Splunk може стати кращим вибором. Якщо вам потрібен більш настроюваний і масштабований інструмент, який можна пристосувати до ваших конкретних потреб, Elastic/ELK може бути кращим вибором.
Програмне забезпечення Elastic/ELK в Україну постачає компанія Ідеалсофт. Крім того, співробітники компанії можуть надати додаткову консультацію та організувати відеоконференцію з розробником та його відділом підтримки.



